Inference Templates
Inference templates are used to preset a set of reusable runtime configurations for AI inference instances. When creating an instance, selecting a template applies the type, image, CPU, memory, GPU, data disk, mounted models, and port mapping settings all at once.
It can be understood as the "standard specification for inference instances". The clearer the template configuration, the more stable batch creation, scaling, rollback, and troubleshooting will be. This document uses Ollama templates as an example to illustrate how to use inference templates; other inference engines will be covered later.
Quick Start
Creating an inference template generally involves the following steps:
- Prepare Image, Model, and GPU Environment: Confirm the target type, AI Image, and GPU environment are ready; this document uses
Ollamatemplates as an example. If you want the template to pre-mount models, prepare the target models in the Inference Model Library in advance. - Create or Edit Template: In the console, go to AI > Inference > Inference Templates, create a new template or modify the platform's preset template.
- Fill in Template Configuration: Set the type, image, CPU, memory, data disk, GPU, port mapping, and mounted models as needed.
- Use Template to Create Instance: Go to AI > Inference > Inference Instances, select the template to create an instance and complete verification.
1. Prerequisites
Before creating a template, it is recommended to confirm the following:
- You have identified the type of template to create; this document uses
Ollamatemplates as an example. - An AI Image matching the template type has been prepared.
- If you want the template to pre-mount models, the target models have been prepared in the Inference Model Library.
- The target node has sufficient GPU, CPU, memory, and data disk capacity.
- If the template needs to pull models or images online, the node has network connectivity to access the target repositories.
Templates only define default specifications and do not "automatically create resources" for you. If the node lacks GPU, VRAM, memory, or storage, even if the template can be saved, subsequent instance creation may still fail during scheduling or startup.
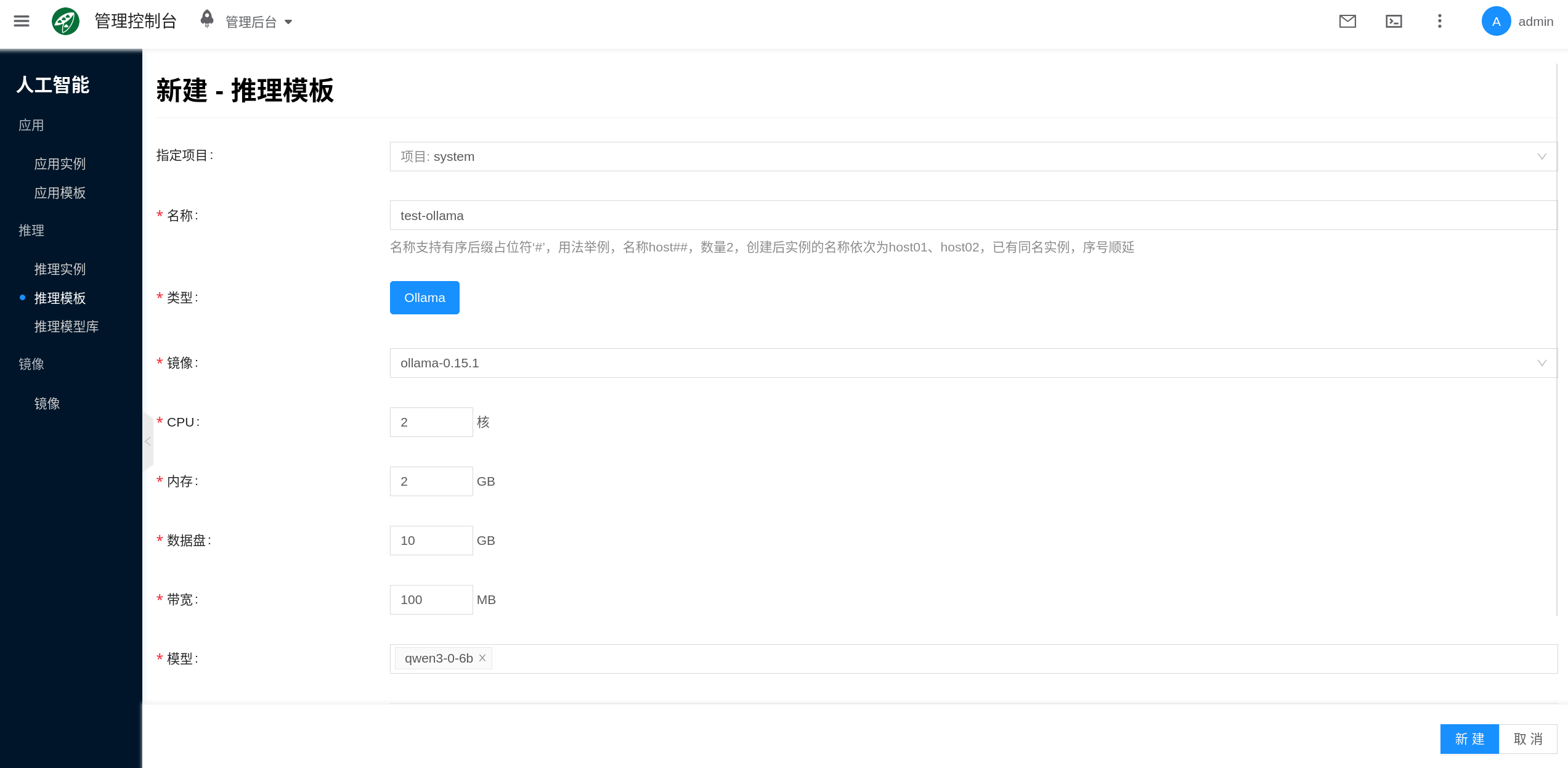
2. Create or Edit Template
The console entry is AI > Inference > Inference Templates.
- Click New, or select an existing template and click Edit.
- Select the template type; this document uses
Ollamaas an example. - Fill in the template name and complete the image, specifications, model, and port configurations.
- Save the template.
The platform generally provides preset default templates, and you can also modify them directly, such as updating the GPU model, data disk size, or mounted models.
3. Use Template to Create Instance
After saving the template, go to AI > Inference > Inference Instances to create an instance. Selecting the corresponding template will reuse the main configurations from the template. Using Ollama as the current example, refer directly to Ollama for instance creation and verification.
Core Configuration Items
Common configuration items for inference templates are as follows:
| Configuration Item | Purpose | Usage Recommendations |
|---|---|---|
| Type | Specifies the inference engine for the template | Must be consistent with the image and mounted model types; this document uses Ollama as an example |
| AI Image | Specifies the container image used at instance runtime | Select an image matching the template type with a specific version |
| CPU / Memory | Determines the base resources for the inference service | Even when VRAM is sufficient, CPU and memory still affect loading speed, concurrency, and stability |
| Data Disk | Provides persistent storage for models, cache, and runtime data | Inference templates must plan for data disks; a disk that is too small will cause model download or mount failures |
| GPU | Determines whether the model can be loaded and the throughput ceiling | Focus on GPU model, VRAM, and quantity |
| Mounted Models | Pre-associates models from the inference model library | Mounted model types must match the template type |
| Port Mapping | Exposes container ports for external access | Different engines use different ports; for Ollama, the common port is 11434 |
| Bandwidth | Limits container network throughput | Consider this when downloading models/images online or providing external APIs |
Type and Image
The template type determines the instance runtime behavior and the scope of selectable images and models. This document uses Ollama templates as an example, highlighting the following validation relationships:
- An
Ollamatemplate should select anOllamatype image. - Models mounted to the template should also match the
Ollamatemplate type.
If the image or mounted model type does not match, the template cannot be saved.
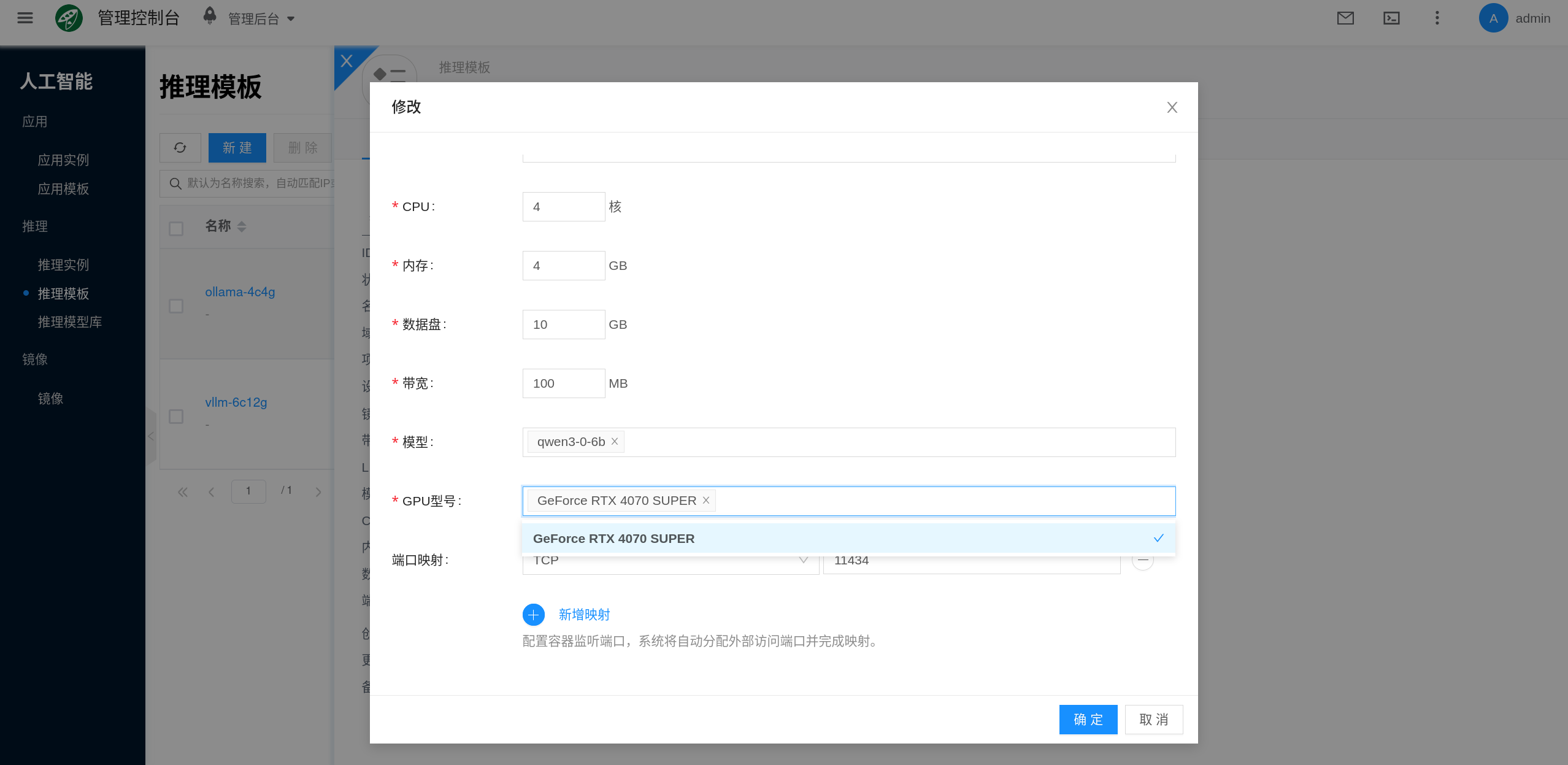
CPU, Memory, GPU, and Data Disk
These fields determine whether the template can support stable operation of the target model:
- CPU: Affects model loading, request queuing, and some preprocessing tasks.
- Memory: Affects the inference process, caching, and runtime stability; insufficient memory may cause OOM or frequent restarts.
- GPU: Determines whether the large model can fit into VRAM, and also affects concurrency capacity and latency performance.
- Data Disk: Used to store model files, cache, and runtime data; this is a critical item in inference templates.
For inference templates, the data disk is not an optional "add-on". Using the Ollama template in this document as an example, the platform needs to persist the model directory:
- Ollama's model directory is located at
/root/.ollama/models - This directory relies on persistent storage to retain models and cache
If you plan to mount multiple models, or want to continue reusing cache after instance restarts, it is recommended to increase the data disk size rather than relying on the container's ephemeral layer.
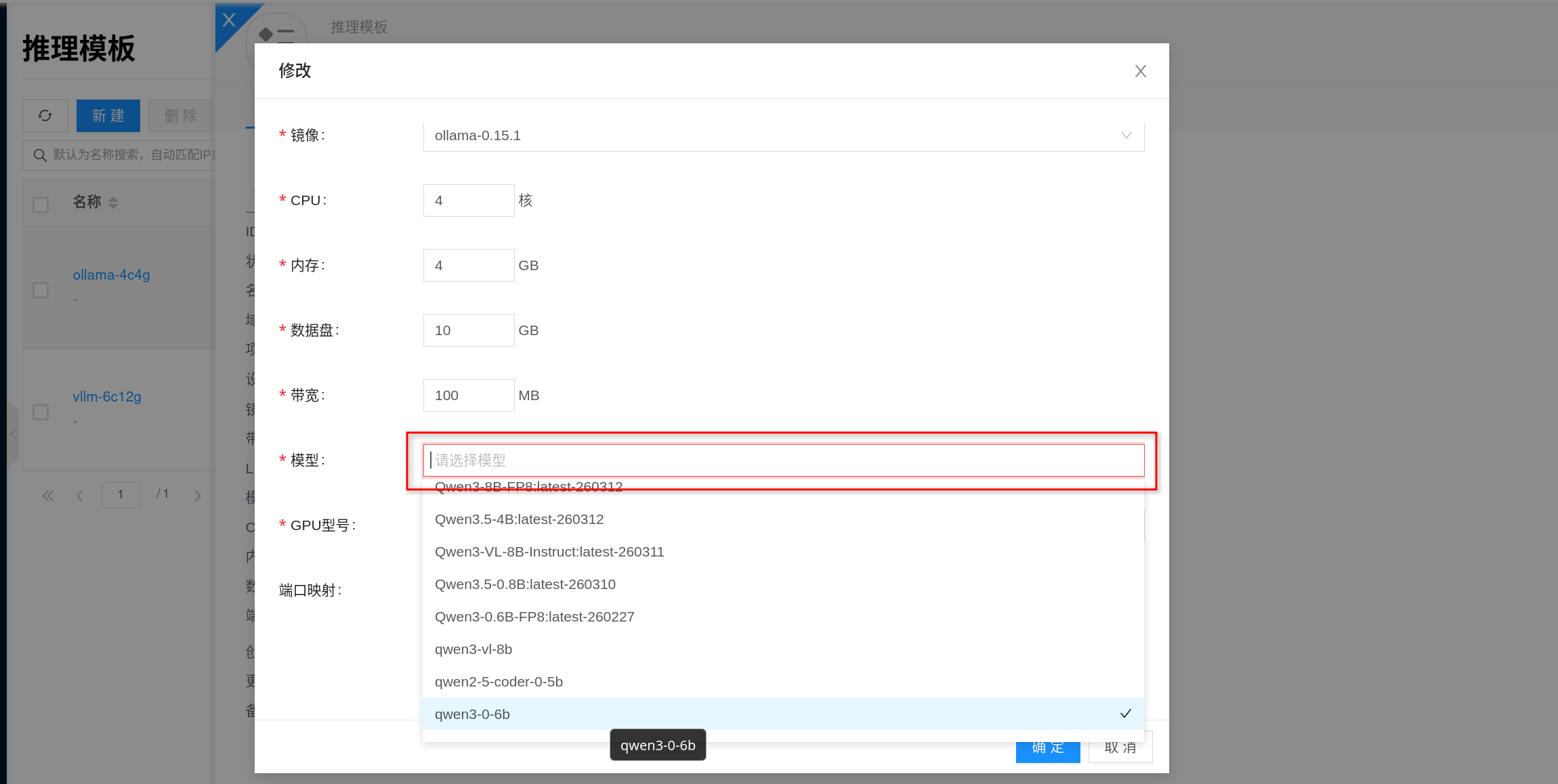
Mounted Models
Templates support pre-mounting models from the Inference Model Library. This way, when creating an instance from the template, models are carried over with the template, reducing the need for manual selection or online downloading each time.
The console links to the inference model library by default; if there are no suitable models in the model library yet, the template can be saved without mounting models and supplemented later.
Note:
- The mounted model type must match the template type; in this example, an
Ollamatemplate should mountOllamamodels. - A template can mount multiple models.
- After instance creation, it inherits the mounted model list from the template.
- Models pre-mounted by the template typically cannot be directly deleted or disabled in the model library without first removing the template reference.
If models in the model library have auto-caching enabled, the platform will perform node-side caching based on the model's associated image, which usually helps reduce the wait time during first startup.
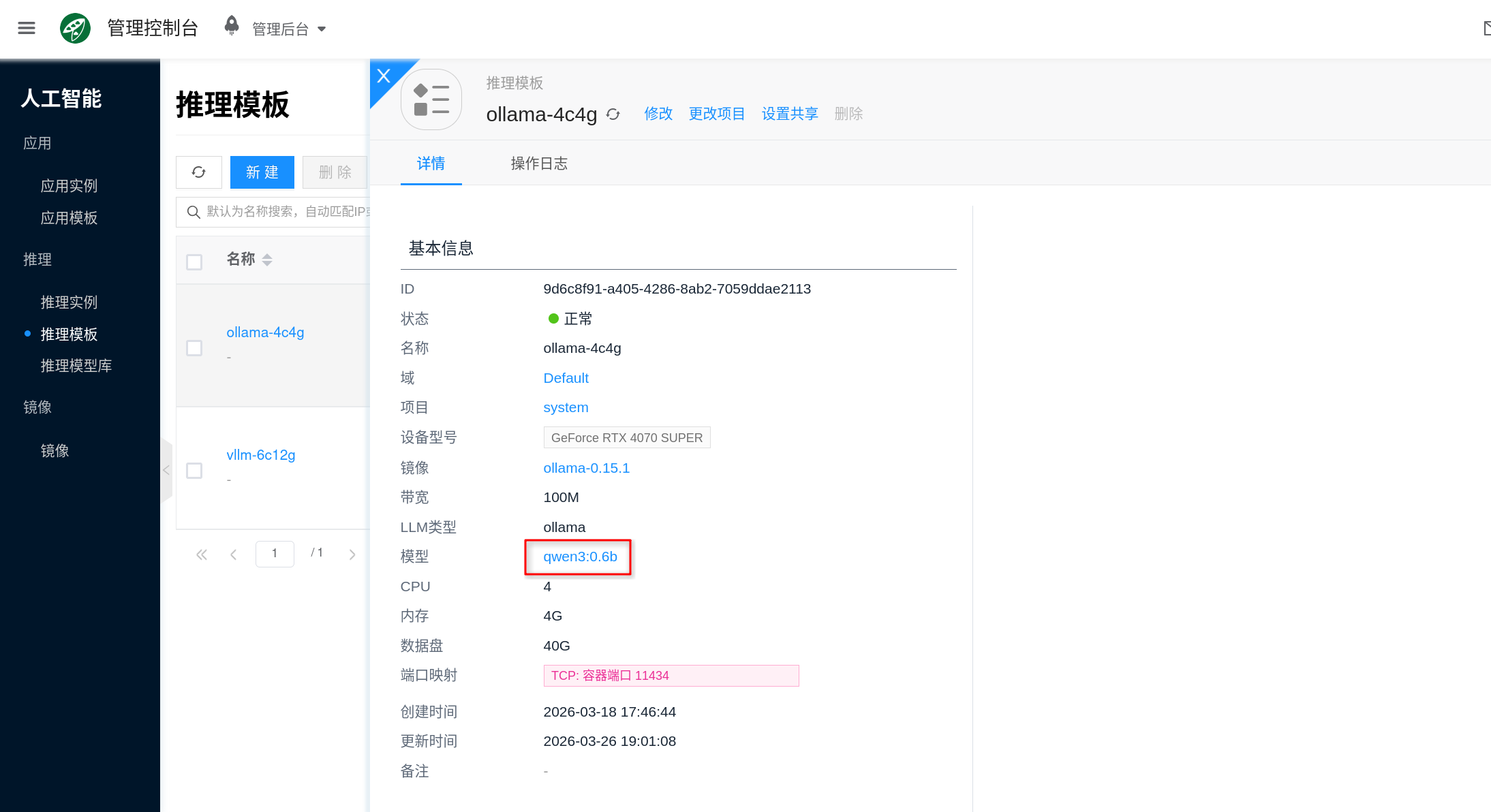
Port Mapping and Network
The port mapping in the template determines how the instance service is exposed externally. Different inference engines may have different default ports; this document uses Ollama as an example, which typically exposes 11434.
Additionally:
- Bandwidth: Affects API throughput and online model download speed.
- Host: If you need to pin the instance to a specific GPU node, you can specify it during instance creation.
- Network: You can choose automatic scheduling or specify an existing subnet; the final configuration is determined at the instance level.
Relationship Between Templates and Instances
Inference templates provide "default values", while inference instances carry the "actual runtime state". Understanding this relationship helps avoid many operational misunderstandings:
- When creating a new instance: The instance inherits the resource specifications, image, mounted models, port mapping, and other main configurations from the template.
- After modifying a template: Changes typically only affect subsequently created instances; already running instances will not automatically sync to the new template configuration.
- During upgrades or rollbacks: It is recommended to modify the template first and recreate the instance, or perform explicit specification/image change operations on the instance side.
If you plan to maintain a set of standardized inference environments long-term, it is recommended to plan multiple templates by model size, GPU tier, or purpose, such as "7B test template", "32B production template", or "Ollama validation template".
FAQ
Template save fails with image or model type mismatch error
- Check whether the template type matches the AI Image type.
- Check whether the mounted model comes from a Inference Model Library entry of the same type.
- In this example, do not mount non-
Ollamatype images or models to anOllamatemplate.
Template was created successfully, but instance still fails to schedule
- A template being saveable does not mean the running node has sufficient resources.
- Focus on checking whether GPU model, VRAM, CPU, memory, and data disk meet the requirements.
- If a host was specified, also confirm that the node actually has allocatable GPU and storage resources.
Why do existing instances not change after modifying the template?
Templates are primarily used for subsequent creation. Already running instances typically do not automatically follow template changes; you need to perform the rebuild process on the instance side separately.
How to estimate data disk size?
- Ollama: Focus on estimating the model volume in
/root/.ollama/modelsand future cache growth. - If multiple models will be mounted, it is recommended to reserve space based on "total model files + cache + future growth", rather than estimating based on a single model size alone.